Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
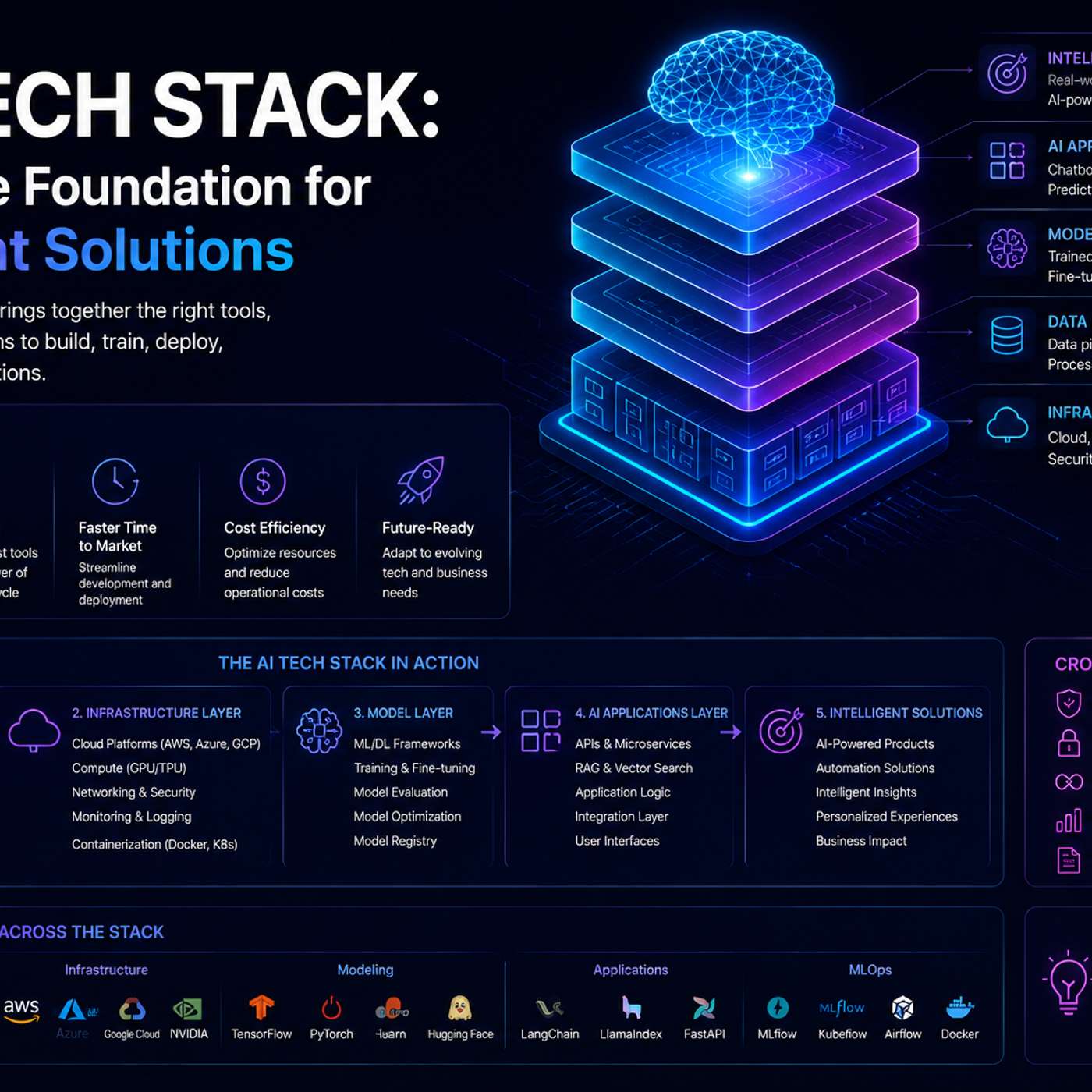
The next significant evolution in AI infrastructure is the shift to multimodal systems. Future tech stacks must move beyond single-modality paradigms (like text-only) to seamlessly handle and integrate text, images, audio, and video within a single, unified architecture.
Related Insights
Human understanding is the ability to connect new information to a global, unified model of the universe. Until recently, AI models were isolated (e.g., a chess model). The major advance with large multimodal models is their ability to create a single, cohesive reality model, enabling true, generalizable understanding.

Google's Embedding 2 model is a significant infrastructure upgrade because it is 'natively multimodal.' This allows AI to directly understand and retrieve images, diagrams, and text without first converting non-text data into lossy captions. This makes internal knowledge bases and co-pilots dramatically more effective and accurate for enterprises.

Instead of interacting with a single LLM, users will increasingly call an API that represents a "system as a model." Behind the scenes, this triggers a complex orchestration of multiple specialized models, sub-agents, and tools to complete a task, while maintaining a simple user experience.

AI apps that require users to select a mode like 'image' or 'text' before a query are revealing their underlying technical limitations. A truly intelligent, multimodal system should infer user intent directly from the prompt within a single conversational flow, rather than relying on a clumsy UI to route the request.

The current focus on LLMs is a temporary phase. The true leap towards AGI will come from multi-sensory models that can process and integrate visual, auditory, and other data streams simultaneously, much like a human does. This moves AI from text generation to real-world understanding.

The future of creative AI is moving beyond simple text-to-X prompts. Labs are working to merge text, image, and video models into a single "mega-model" that can accept any combination of inputs (e.g., a video plus text) to generate a complex, edited output, unlocking new paradigms for design.

While today's focus is on text-based LLMs, the true, defensible AI battleground will be in complex modalities like video. Generating video requires multiple interacting models and unique architectures, creating far greater potential for differentiation and a wider competitive moat than text-based interfaces, which will become commoditized.

While language models are becoming incrementally better at conversation, the next significant leap in AI is defined by multimodal understanding and the ability to perform tasks, such as navigating websites. This shift from conversational prowess to agentic action marks the new frontier for a true "step change" in AI capabilities.

Current multimodal models shoehorn visual data into a 1D text-based sequence. True spatial intelligence is different. It requires a native 3D/4D representation to understand a world governed by physics, not just human-generated language. This is a foundational architectural shift, not an extension of LLMs.

The repeated mention of the 'Duccio' framework for multimodal feature extraction signals a key trend. Advanced recommendation systems are moving beyond single data types, integrating audio, visual, and textual data to build a more holistic understanding of user preferences and products.
