Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
A slowdown in compute growth may have a squared negative effect on AI progress. It not only reduces resources for training larger models but also stifles the discovery of new algorithms, as breakthroughs like the Transformer required immense compute for experimentation. This double impact could significantly delay major capabilities milestones.

Related Insights
While more data and compute yield linear improvements, true step-function advances in AI come from unpredictable algorithmic breakthroughs like Transformers. These creative ideas are the most difficult to innovate on and represent the highest-leverage, yet riskiest, area for investment and research focus.

The progression from early neural networks to today's massive models is fundamentally driven by the exponential increase in available computational power, from the initial move to GPUs to today's million-fold increases in training capacity on a single model.

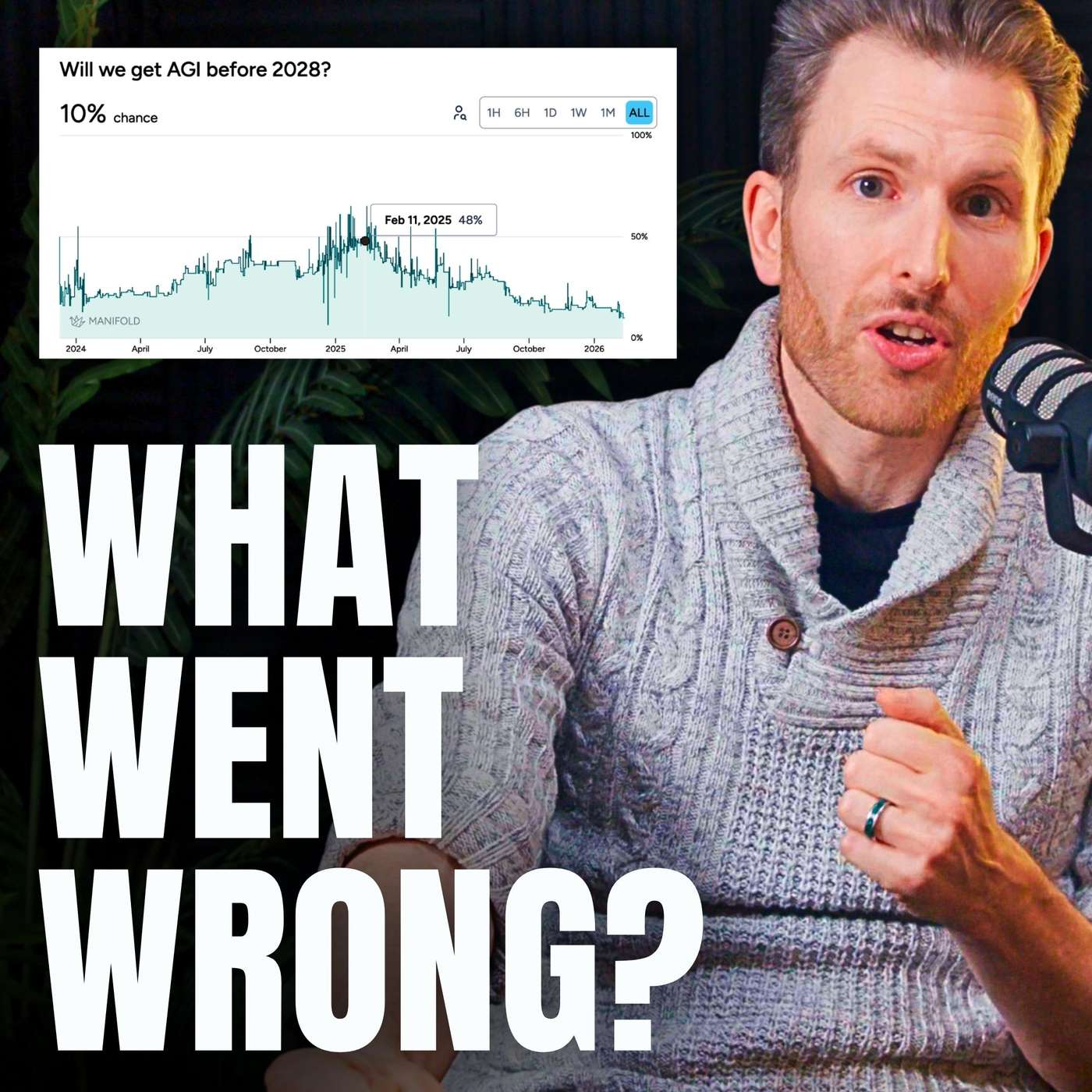
For the first time in years, the perceived leap in LLM capabilities has slowed. While models have improved, the cost increase (from $20 to $200/month for top-tier access) is not matched by a proportional increase in practical utility, suggesting a potential plateau or diminishing returns.

Over two-thirds of reasoning models' performance gains came from massively increasing their 'thinking time' (inference scaling). This was a one-time jump from a zero baseline. Further gains are prohibitively expensive due to compute limitations, meaning this is not a repeatable source of progress.
A "software-only singularity," where AI recursively improves itself, is unlikely. Progress is fundamentally tied to large-scale, costly physical experiments (i.e., compute). The massive spending on experimental compute over pure researcher salaries indicates that physical experimentation, not just algorithms, remains the primary driver of breakthroughs.

The plateauing performance-per-watt of GPUs suggests that simply scaling current matrix multiplication-heavy architectures is unsustainable. This hardware limitation may necessitate research into new computational primitives and neural network designs built for large-scale distributed systems, not single devices.
The focus in AI has evolved from rapid software capability gains to the physical constraints of its adoption. The demand for compute power is expected to significantly outstrip supply, making infrastructure—not algorithms—the defining bottleneck for future growth.

The history of AI, such as the 2012 AlexNet breakthrough, demonstrates that scaling compute and data on simpler, older algorithms often yields greater advances than designing intricate new ones. This "bitter lesson" suggests prioritizing scalability over algorithmic complexity for future progress.
The era of guaranteed progress by simply scaling up compute and data for pre-training is ending. With massive compute now available, the bottleneck is no longer resources but fundamental ideas. The AI field is re-entering a period where novel research, not just scaling existing recipes, will drive the next breakthroughs.

The AI industry's exponential growth in consuming compute, electricity, and talent is unsustainable. By 2032, it will have absorbed most available slack from other industries. Further progress will require potentially un-fundable trillion-dollar training runs, creating a critical period for AGI development.