Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
While hardware gets cheaper (Moore's Law), the competitive pressure to release superior AI models leads to exponentially larger and more complex systems. This results in a higher number of "tokens burned" per query, making the cost of delivering a useful answer actually increase with each new generation.

Related Insights
The relationship between computing power and AI model capability is not linear. According to established 'scaling laws,' a tenfold increase in the compute used for training large language models (LLMs) results in roughly a doubling of the model's capabilities, highlighting the immense resources required for incremental progress.

For the first time in years, the perceived leap in LLM capabilities has slowed. While models have improved, the cost increase (from $20 to $200/month for top-tier access) is not matched by a proportional increase in practical utility, suggesting a potential plateau or diminishing returns.

Over two-thirds of reasoning models' performance gains came from massively increasing their 'thinking time' (inference scaling). This was a one-time jump from a zero baseline. Further gains are prohibitively expensive due to compute limitations, meaning this is not a repeatable source of progress.
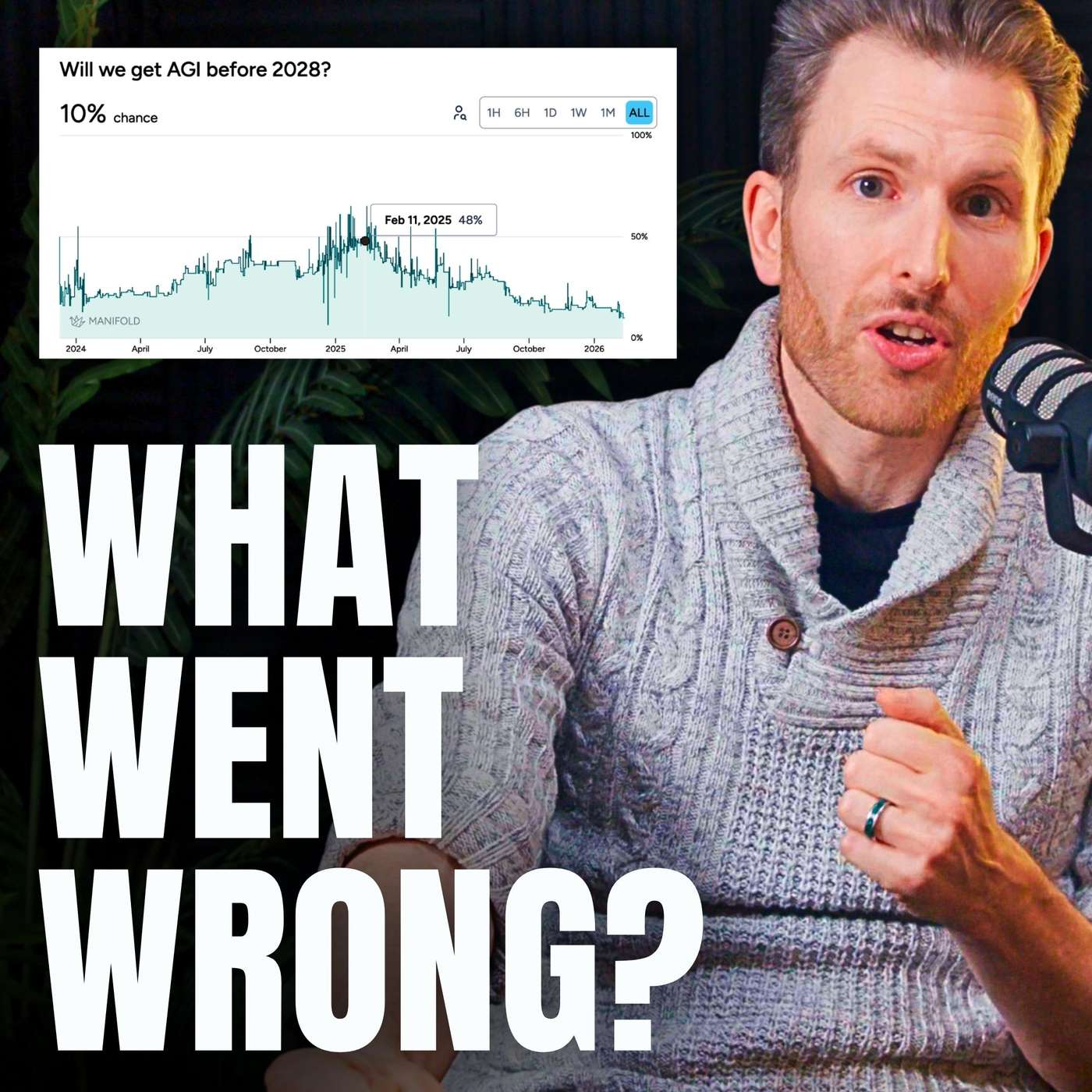
A primary risk for major AI infrastructure investments is not just competition, but rapidly falling inference costs. As models become efficient enough to run on cheaper hardware, the economic justification for massive, multi-billion dollar investments in complex, high-end GPU clusters could be undermined, stranding capital.

A paradox exists where the cost for a fixed level of AI capability (e.g., GPT-4 level) has dropped 100-1000x. However, overall enterprise spend is increasing because applications now use frontier models with massive contexts and multi-step agentic workflows, creating huge multipliers on token usage that drive up total costs.

The cost of AI, priced in "tokens by the drink," is falling dramatically. All inputs are on a downward cost curve, leading to a hyper-deflationary effect on the price of intelligence. This, in turn, fuels massive demand elasticity as more use cases become economically viable.

Software has long commanded premium valuations due to near-zero marginal distribution costs. AI breaks this model. The significant, variable cost of inference means expenses scale with usage, fundamentally altering software's economic profile and forcing valuations down toward those of traditional industries.

While the cost to achieve a fixed capability level (e.g., GPT-4 at launch) has dropped over 100x, overall enterprise spending is increasing. This paradox is explained by powerful multipliers: demand for frontier models, longer reasoning chains, and multi-step agentic workflows that consume exponentially more tokens.
The common goal of increasing AI model efficiency could have a paradoxical outcome. If AI performance becomes radically cheaper ("too cheap to meter"), it could devalue the massive investments in compute and data center infrastructure, creating a financial crisis for the very companies that enabled the boom.
While the cost for GPT-4 level intelligence has dropped over 100x, total enterprise AI spend is rising. This is driven by multipliers: using larger frontier models for harder tasks, reasoning-heavy workflows that consume more tokens, and complex, multi-turn agentic systems.