Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Contrary to popular belief, many significant boosts in AI model quality don't originate from novel algorithms. Instead, they come from the less glamorous work of identifying and fixing subtle bugs within the data and model training pipelines.

Related Insights
The core of an effective AI data flywheel is a process that captures human corrections not as simple fixes, but as perfectly formatted training examples. This structured data, containing the original input, the AI's error, and the human's ground truth, becomes a portable, fine-tuning-ready asset that directly improves the next model iteration.

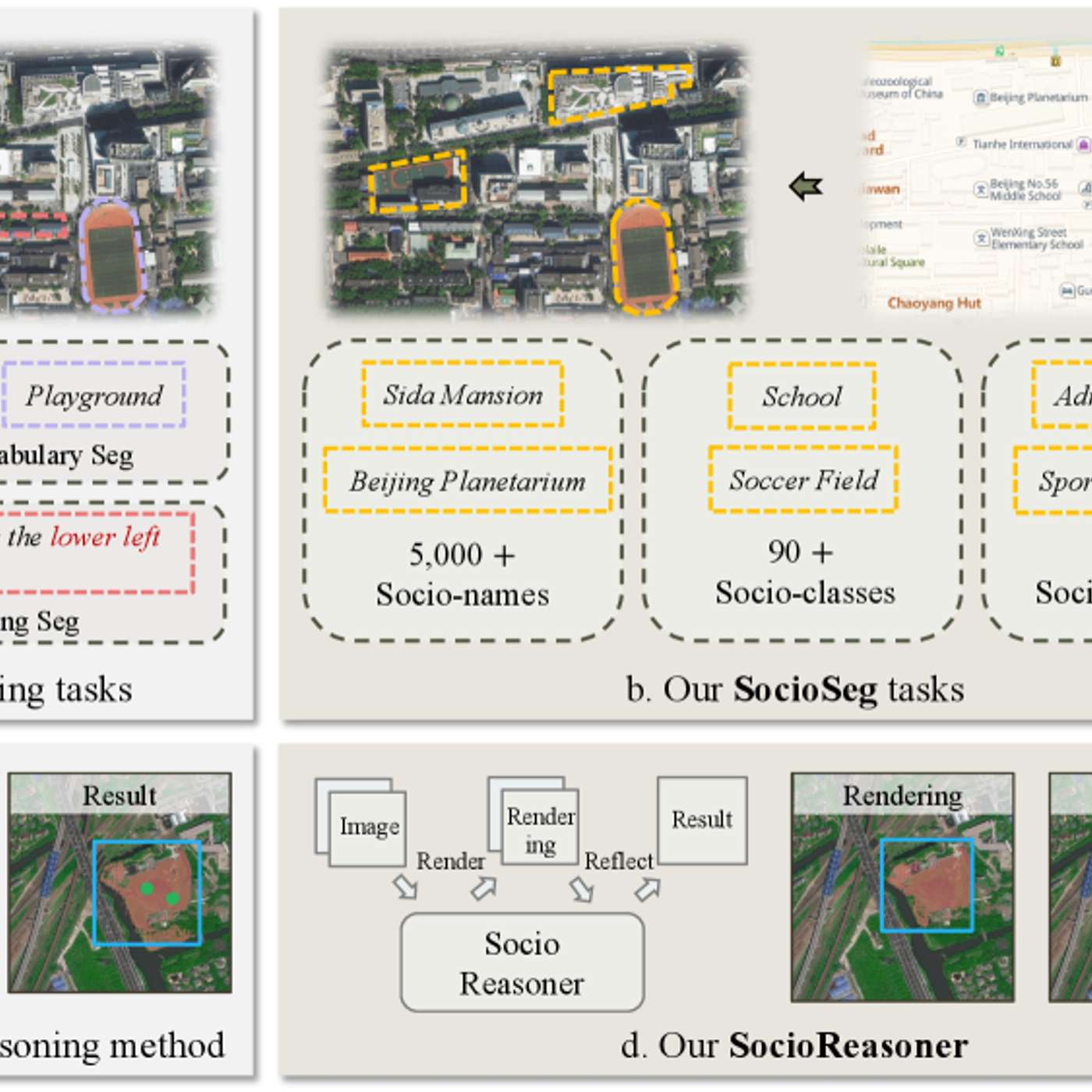
The researchers' failure case analysis is highlighted as a key contribution. Understanding why the model fails—due to ambiguous data or unusual inputs—provides a realistic scope of application and a clear roadmap for improvement, which is more useful for practitioners than high scores alone.
People overestimate AI's 'out-of-the-box' capability. Successful AI products require extensive work on data pipelines, context tuning, and continuous model training based on output. It's not a plug-and-play solution that magically produces correct responses.

The critical challenge in AI development isn't just improving a model's raw accuracy but building a system that reliably learns from its mistakes. The gap between an 85% accurate prototype and a 99% production-ready system is bridged by an infrastructure that systematically captures and recycles errors into high-quality training data.
The effectiveness of an AI system isn't solely dependent on the model's sophistication. It's a collaboration between high-quality training data, the model itself, and the contextual understanding of how to apply both to solve a real-world problem. Neglecting data or context leads to poor outcomes.

Contrary to the "more data is better" mantra, scaling with bad data actively degrades model performance. Undeduplicated data makes models "forgetful" and less intelligent over time. You cannot overcome poor data quality simply by adding more compute; better, cleaner data is more effective.

Microsoft's research found that training smaller models on high-quality, synthetic, and carefully filtered data produces better results than training larger models on unfiltered web data. Data quality and curation, not just model size, are the new drivers of performance.

The primary reason multi-million dollar AI initiatives stall or fail is not the sophistication of the models, but the underlying data layer. Traditional data infrastructure creates delays in moving and duplicating information, preventing the real-time, comprehensive data access required for AI to deliver business value. The focus on algorithms misses this foundational roadblock.

Research shows that AI models trained on smaller, high-quality datasets are more efficient and capable than those trained on the unfiltered internet. This signals an industry shift from a 'more data' to a 'right data' paradigm, prioritizing quality over sheer quantity for better model performance.

When an AI-coded feature is flawed, the instinct is to patch the specific output. A more effective, long-term approach is to analyze *why* your agent system produced a bad result and improve the underlying agent, skill, or process that failed.
