Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Relying on prompt engineering for safety is insufficient and easily bypassed. The expert consensus is to build safeguards directly into the system's architecture. Architectural controls are immutable during runtime, whereas prompt-level controls can be manipulated or overridden by clever user inputs.

Related Insights
Simple refusal mechanisms in AI models are easily bypassed by motivated actors. Effective biosecurity requires deeper interventions, such as curating training data to exclude sensitive biological information or implementing strict access controls for the most powerful models, ensuring they aren't publicly available.

Instead of maintaining an exhaustive blocklist of harmful inputs, monitoring a model's internal state identifies when specific neural pathways associated with "toxicity" are activated. This proactively detects harmful generation intent, even from novel or benign-looking prompts, solving the cat-and-mouse game of prompt filtering.

While guardrails in prompts are useful, a more effective step to prevent AI agents from hallucinating is careful model selection. For instance, using Google's Gemini models, which are noted to hallucinate less, provides a stronger foundational safety layer than relying solely on prompt engineering with more 'creative' models.

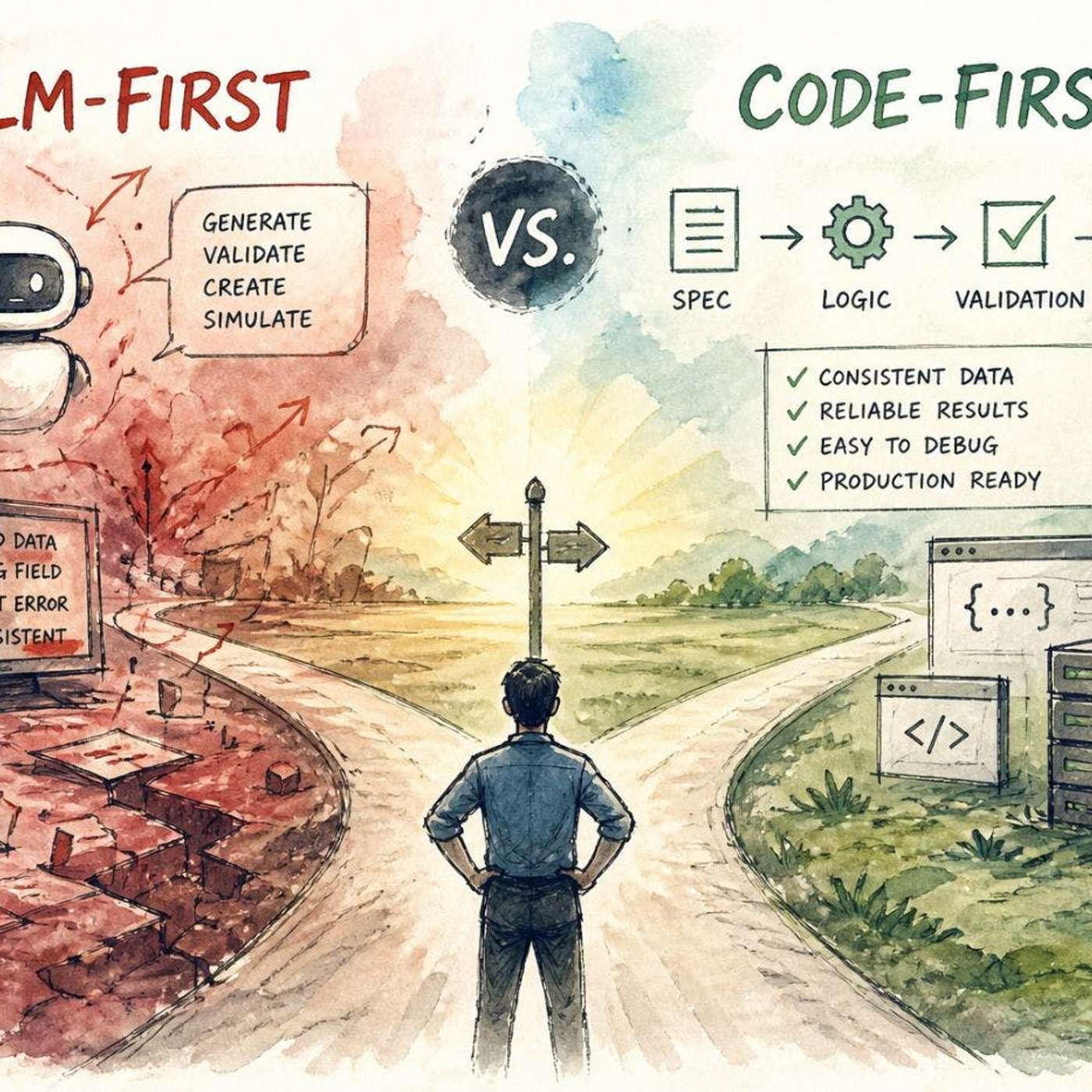
Don't give LLMs full control. Use deterministic code for core logic, validation, and enforcing rules. Delegate only tasks requiring flexibility or understanding of unstructured input to the LLM, treating it as a specialized component, not the entire system.
Claiming a "99% success rate" for an AI guardrail is misleading. The number of potential attacks (i.e., prompts) is nearly infinite. For GPT-5, it's 'one followed by a million zeros.' Blocking 99% of a tested subset still leaves a virtually infinite number of effective attacks undiscovered.

Contrary to the popular belief that generative AI is easily jailbroken, modern models now use multi-step reasoning chains. They unpack prompts, hydrate them with context before generation, and run checks after generation. This makes it significantly harder for users to accidentally or intentionally create harmful or brand-violating content.

The conversation around Agentic AI has matured beyond abstract policies. The consensus among consultancies, tech firms, and academics is that effective governance requires embedding controls, like access management and validation, directly into the system's architecture as a core design principle.
Current AI safety solutions primarily act as external filters, analyzing prompts and responses. This "black box" approach is ineffective against jailbreaks and adversarial attacks that manipulate the model's internal workings to generate malicious output from seemingly benign inputs, much like a building's gate security can't stop a resident from causing harm inside.
To balance AI capability with safety, implement "power caps" that prevent a system from operating beyond its core defined function. This approach intentionally limits performance to mitigate risks, prioritizing predictability and user comfort over achieving the absolute highest capability, which may have unintended consequences.

A comprehensive AI safety strategy mirrors modern cybersecurity, requiring multiple layers of protection. This includes external guardrails, static checks, and internal model instrumentation, which can be combined with system-level data (e.g., a user's refund history) to create complex, robust security rules.