Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
To ensure high reliability, don't wait for clients to report issues. Implement "watchdogs" to auto-restart crashed components. More importantly, configure each client's agent with its own email address to proactively alert you directly when a job or skill fails, allowing you to fix it before the customer even notices.

Related Insights
An AI agent monitors a support inbox, identifies a bug report, cross-references it with the GitHub codebase to find the issue, suggests probable causes, and then passes the task to another AI to write the fix. This automates the entire debugging lifecycle.

Integrate AI agents directly into core workflows like Slack and institutionalize them as the "first line of response." By tagging the agent on every new bug, crash, or request, it provides an initial analysis or pull request that humans can then review, edit, or build upon.

Cursor's "cloud agent diagnosis" command allows a primary agent to spin up specialized sub-agents that use integrations like Datadog to explore logs and diagnose another agent's failure. This creates a multi-agent system where agents act as external debuggers for each other.
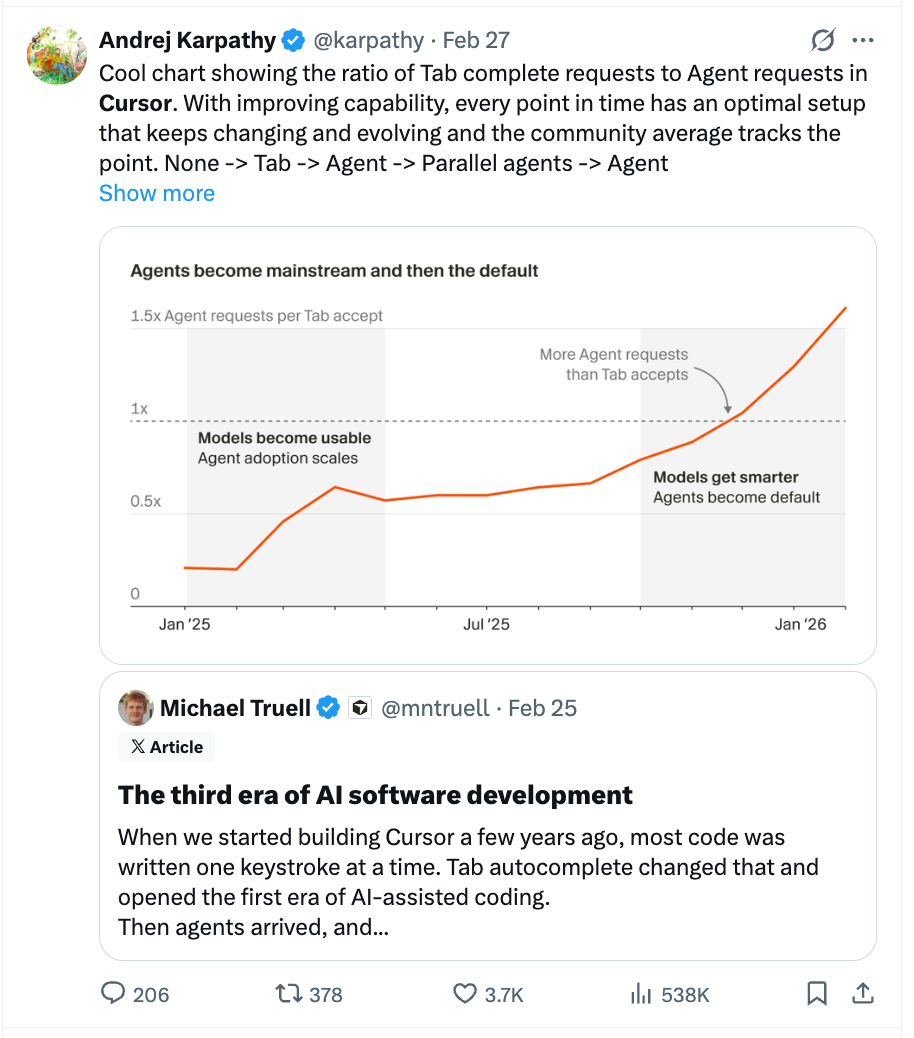
AI agents solve the classic "recall vs. precision" problem in site reliability. Vercel's CTO explains you can set monitoring thresholds very aggressively. Instead of paging a human, an agent investigates first, filtering out false positives and only escalating true emergencies, thus eliminating alert fatigue.

Task your AI agent with its own maintenance by creating a recurring job for it to analyze its own files, skills, and schedules. This allows the AI to proactively identify inefficiencies, suggest optimizations, and find bugs, such as a faulty cron scheduler.

The traditional Quarterly Business Review (QBR) is an outdated, reactive process based on past events. An AI agent can act as a continuous, real-time QBR, constantly monitoring customer progress, identifying gaps, and proactively engaging them, preventing issues before they happen.

Expect your AI agent's skills to fail initially. Treat each failure as a learning opportunity. Work with the agent to identify and fix the error, then instruct it to update the original skill file with the solution. This recursive process makes the skill more robust over time.
Instead of just fielding calls, the contact center can act as an early warning system. By monitoring call influx and themes in real-time, leaders can identify systemic issues, like a website bug, and proactively alert agents and the broader business, turning reactive support into a strategic intelligence hub.

Treat custom AI agents like junior employees, not finished software. They require daily check-ins to monitor for bugs, performance issues, and regressions. There is no "set and forget"—a human must actively manage the agent every day for it to succeed.
To automate bug fixing, connect an AI agent to your error reporting (Sentry), database (Supabase), and log drains (Acxiom). When a bug is reported, the agent can autonomously replay events from logs, diagnose the root cause of the failure, and eventually fix it, creating a powerful self-healing loop for your application.
