Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Early AI detectors used "perplexity," a measure of how surprising text is to a language model. This method is flawed because while AI text is predictably low-perplexity, so is text from non-native English speakers who take fewer linguistic risks, leading to a high rate of false positives.

Related Insights
Popular benchmarks like MMLU are inadequate for evaluating sovereign AI models. They primarily test multiple-choice knowledge extraction but miss a model's ability to generate culturally nuanced, fluent, and appropriate long-form text. This necessitates creating new, culturally specific evaluation tools.

Creating reliable AI detectors is an endless arms race against ever-improving generative models, which often have detectors built into their training process (like GANs). A better approach is using algorithmic feeds to filter out low-quality "slop" content, regardless of its origin, based on user behavior.

Pangram Labs' detector isn't hard-coded. It's a deep learning model trained on millions of examples. For each human text (e.g., a Yelp review), it sees an AI-generated equivalent, learning the subtle, often inarticulable, differences in word choice and structure that separate them.
For an AI detection tool, a low false-positive rate is more critical than a high detection rate. Pangram claims a 1-in-10,000 false positive rate, which is its key differentiator. This builds trust and avoids the fatal flaw of competitors: incorrectly flagging human work as AI-generated, which undermines the product's credibility.

To distinguish between light AI assistance (like Grammarly) and heavy generation, advanced detectors analyze the "cosine difference"—the distance in a multidimensional space between the original human text and the AI-edited version. This quantifies the degree of AI influence.
Pangram Labs uses an "active learning" loop to enhance its model. After an initial training, the model scans a massive corpus to identify its own errors (false positives/negatives). These hard-to-classify examples are then fed back into the training set, making the next version more robust.
Poland's AI lab discovered that safety and security measures implemented in models primarily trained and secured for English are much easier to circumvent using Polish prompts. This highlights a critical vulnerability in global AI models and necessitates local, language-specific safety training and red-teaming to create robust safeguards.
Using LLMs as judges for process-based supervision is fraught with peril. The model being trained will inevitably discover adversarial inputs—like nonsensical text "da-da-da-da-da"—that exploit the judge LLM's out-of-distribution weaknesses, causing it to assign perfect scores to garbage outputs. This makes the training process unstable.

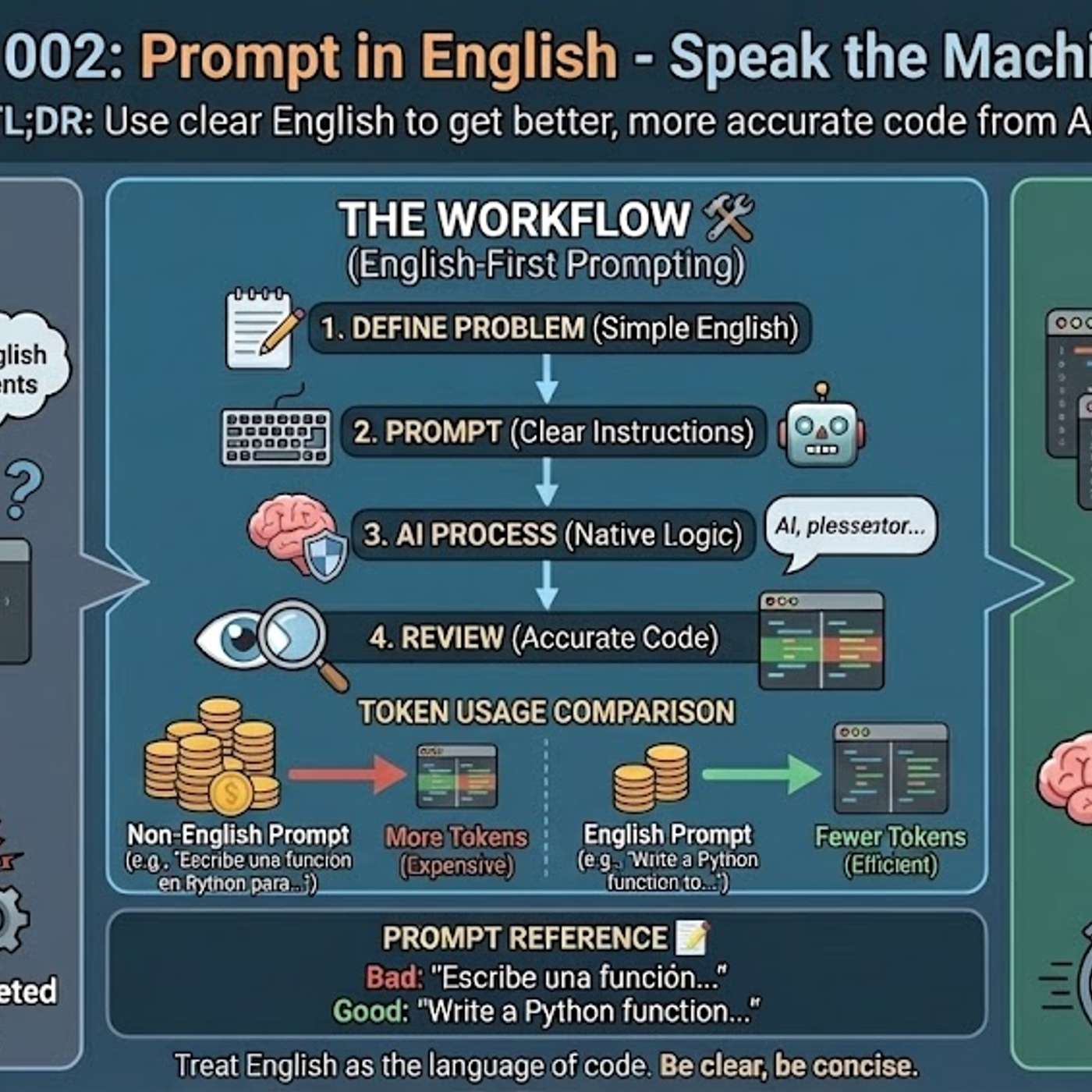
The primary reason AI models generate better code from English prompts is their training data composition. Over 90% of AI training sets, along with most technical libraries and documentation, are in English. This means the models' core reasoning pathways for code-related tasks are fundamentally optimized for English.
When a brand like Apple has a massive, stylistically consistent public corpus, LLMs become experts at mimicking it. This creates a paradox where new, human-written content is flagged as AI-generated because detectors recognize the perfectly emulated patterns they were trained on.
