Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Professor Kyunghyun Cho highlights a key tension in AI research. High-fidelity predictive models (like OpenAI's Sora) are computationally regular and scalable on current hardware. However, human-like intelligence relies on abstract, high-level reasoning that skips unnecessary details, a more efficient but computationally challenging approach.

Related Insights
AI models struggle to plan at different levels of abstraction simultaneously. They can't easily move from a high-level goal to a detailed task and then back up to adjust the high-level plan if the detail is blocked, a key aspect of human reasoning.

Human understanding is the ability to connect new information to a global, unified model of the universe. Until recently, AI models were isolated (e.g., a chess model). The major advance with large multimodal models is their ability to create a single, cohesive reality model, enabling true, generalizable understanding.

As models become more powerful, the primary challenge shifts from improving capabilities to creating better ways for humans to specify what they want. Natural language is too ambiguous and code too rigid, creating a need for a new abstraction layer for intent.

Language is just one 'keyhole' into intelligence. True artificial general intelligence (AGI) requires 'world modeling'—a spatial intelligence that understands geometry, physics, and actions. This capability to represent and interact with the state of the world is the next critical phase of AI development beyond current language models.

Over two-thirds of reasoning models' performance gains came from massively increasing their 'thinking time' (inference scaling). This was a one-time jump from a zero baseline. Further gains are prohibitively expensive due to compute limitations, meaning this is not a repeatable source of progress.
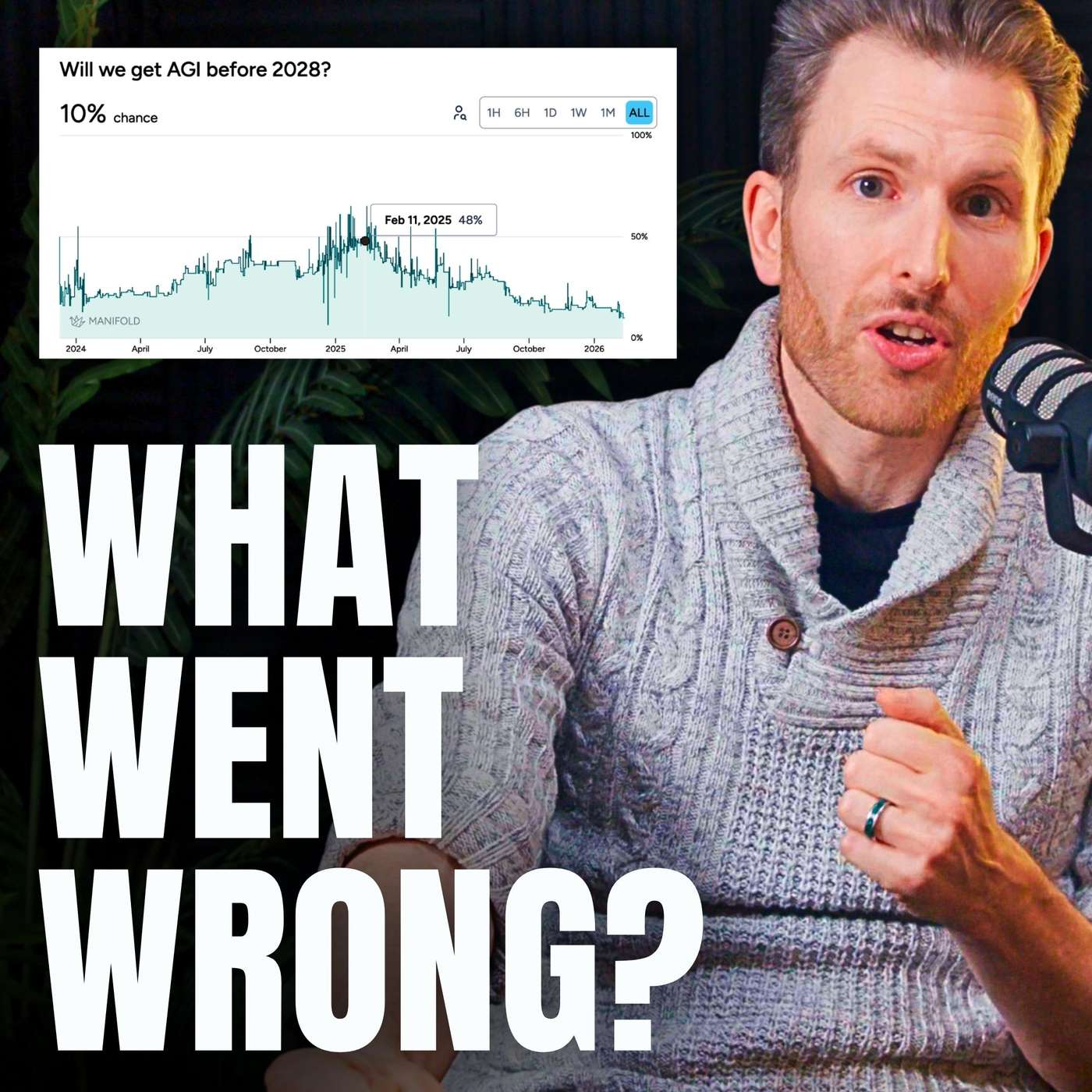
Today's AI boom is fueled by scaling computation, which is a known engineering challenge. The alternative, embedding nuanced, human-like inductive biases, is far harder as it requires a deep understanding of the problem space. This difficulty gap explains why massive models dominate AI development over more targeted, efficient ones—scaling is simply the more straightforward path.
AI's capabilities are highly uneven. Models are already superhuman in specific domains like speaking 150 languages or possessing encyclopedic knowledge. However, they still fail at tasks typical humans find easy, such as continual learning or nuanced visual reasoning like understanding perspective in a photo.

The "bitter lesson" in AI research posits that methods leveraging massive computation scale better and ultimately win out over approaches that rely on human-designed domain knowledge or clever shortcuts, favoring scale over ingenuity.

While a world model can generate a physically plausible arch, it doesn't understand the underlying physics of force distribution. This gap between pattern matching and causal reasoning is a fundamental split between AI and human intelligence, making current models unsuitable for mission-critical applications like architecture.

Prof. Cho outlines two competing visions for world models. One camp believes in high-fidelity, step-by-step prediction (e.g., video generation). The other, which he and Yann LeCun favor, argues for abstract, high-level latent models that can plan without simulating every detail, akin to human thinking.
