Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Kun Chen's 'no mistakes' pipeline includes a testing phase where agents run comprehensive end-to-end tests to check for regressions. Crucially, the agent captures and embeds evidence, like screenshots or videos of the working feature, directly into the PR description for easy human verification.

Related Insights
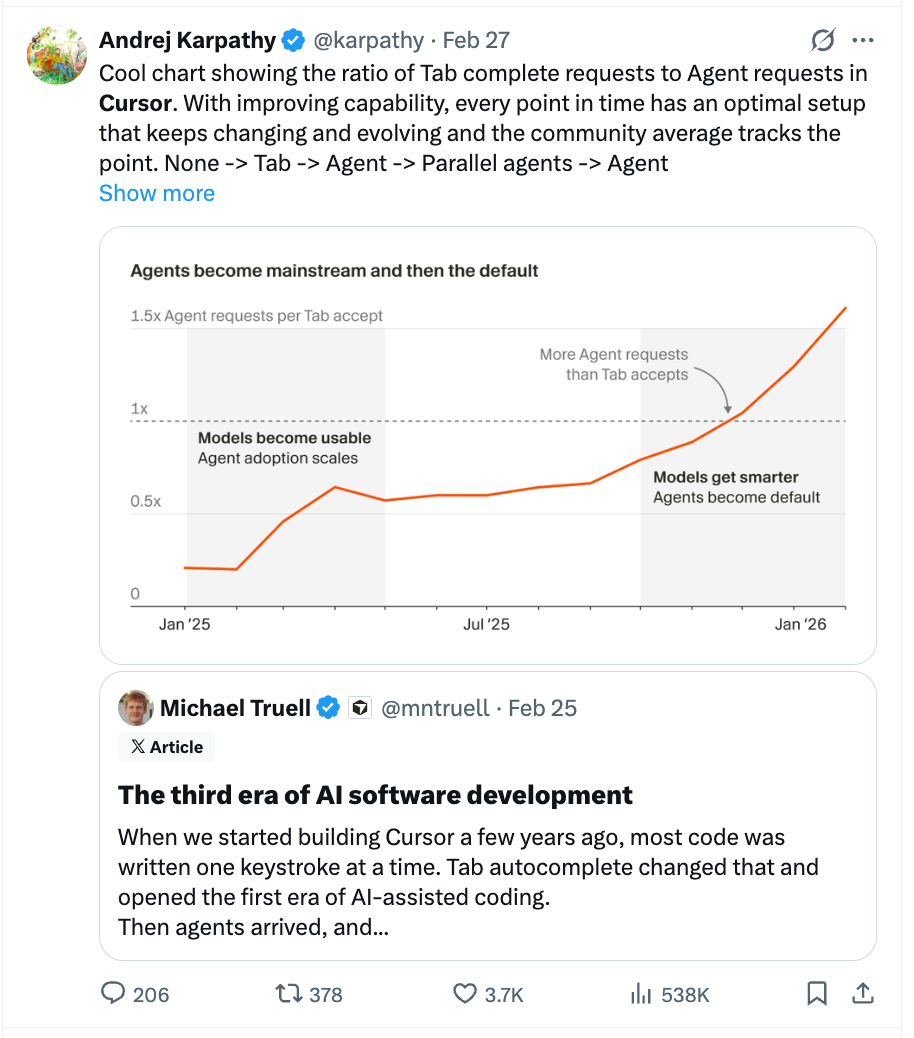
The ease of creating PRs with AI agents shifts the developer bottleneck from code generation to code validation. The new challenge is not writing the code, but gaining the confidence to merge it, elevating the importance of review, testing, and CI/CD pipelines.
Enhance pull requests by using Playwright to automatically screen-record a demonstration of the new feature. This video is then attached to the PR, giving code reviewers immediate visual context of the changes, far beyond what static code can show.
Create a project-specific `agents.md` file to provide agents with high-level context, key file structures, and explicit instructions for tasks like end-to-end testing. This ensures agents perform comprehensive, project-appropriate validation beyond generic unit tests.
As AI generates more code than humans can review, the validation bottleneck emerges. The solution is providing agents with dedicated, sandboxed environments to run tests and verify functionality before a human sees the code, shifting review from process to outcome.

To combat the bottleneck of reviewing massive, AI-generated pull requests, Cursor's agents create video demos of the features they build. This provides a much more accessible entry point for human review than a giant diff, helping to quickly align on the direction.
Use Playwright to give Claude Code control over a browser for testing. The AI can run tests, visually identify bugs, and then immediately access the codebase to fix the issue and re-validate. This creates a powerful, automated QA and debugging loop.
A common failure with AI agents is underspecified prompts leading to incorrect implementations (e.g., a checkbox instead of a toggle). Video demos provide immediate visual feedback, creating a shared artifact that makes these misalignments obvious without needing to run the code locally.
To get the best results from an AI agent, provide it with a mechanism to verify its own output. For coding, this means letting it run tests or see a rendered webpage. This feedback loop is crucial, like allowing a painter to see their canvas instead of working blindfolded.

An agent's effectiveness is limited by its ability to validate its own output. By building in rigorous, continuous validation—using linters, tests, and even visual QA via browser dev tools—the agent follows a 'measure twice, cut once' principle, leading to much higher quality results than agents that simply generate and iterate.
For bug fixes, Cursor's agents can be instructed to first reproduce a bug and create a video of it happening. They then fix it and make a second video showing the same workflow succeeding. This TDD-like "red-green" video proof dramatically increases confidence in the fix.