Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Top-tier data centers operate at extreme efficiency. Google's Borg team aimed for 96%+ node utilization, viewing anything less as a critical failure. This contrasts with MFU (Matrix Multiply Unit) utilization, where best-in-class is 60-70%. Most single-tenant clusters fall far short of Google's standards.
Related Insights
AI companies run private compute clusters at low utilization, similar to early industrial factories each having their own inefficient steam generator. This creates massive waste. The solution is a shared, coordinated compute grid that acts as an independent system operator to drive up utilization across the ecosystem.

The widely discussed GPU supply crunch is only half the problem. There's a severe shortage of suppliers who can operate data centers with the high reliability and SLAs required for mission-critical inference. Out of many providers, only a handful meet the "gold tier" for operational excellence.

The primary bear case for specialized neoclouds like CoreWeave isn't just competition from AWS or Google. A more fundamental risk is a breakthrough in GPU efficiency that commoditizes deployment, diminishing the value of the neoclouds' core competency in complex, optimized racking and setup.

Microsoft Azure imposes a harsh "use-it-or-lose-it" policy on GPU clusters for smaller customers. Even a few hours of underutilization can result in being kicked off and placed at the back of a months-long waiting list, creating major instability for startups.
The advertised per-hour GPU cost is misleading. Because research workloads are spiky and unpredictable, labs over-provision compute. This rampant underutilization means the effective price paid is often 10 times higher than the marketed rate, creating massive deadweight loss.

The primary bottleneck for hyperscalers is access to grid power, not land or chips. Therefore, more efficient cooling systems like Madrone's are not just an operational cost-saver but a strategic enabler, freeing up precious megawatts of power that can be reallocated to revenue-generating GPUs.

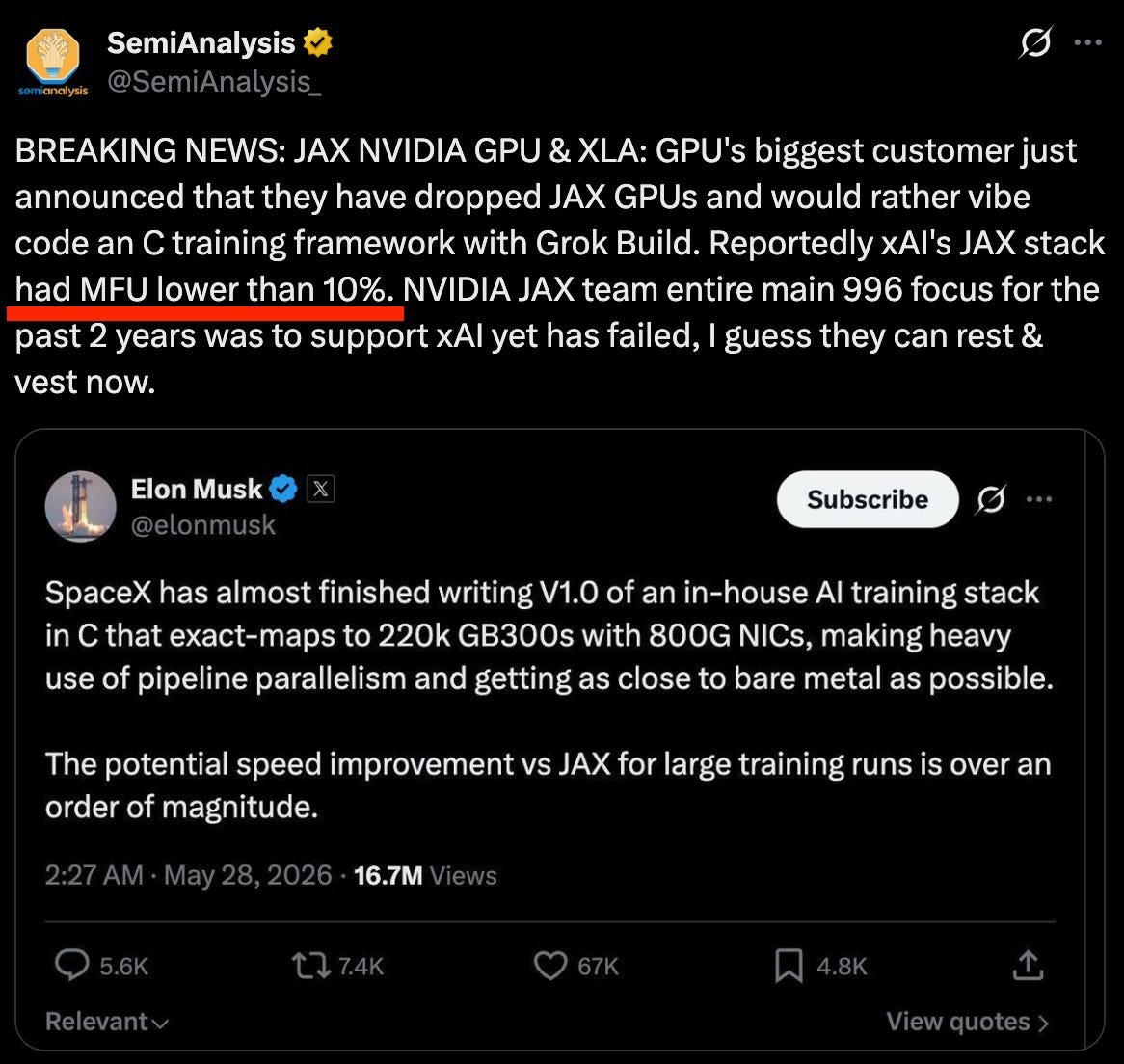
The report of XAI's low GPU utilization reveals a critical, non-obvious bottleneck in AI: it's not just about acquiring compute, but using it efficiently. This 'FLOPS utilization' problem, caused by architectural and load-balancing issues, means billions in hardware sits underused, creating an opportunity for companies that can optimize the compute stack.

To avoid losing their allocated GPUs, some AI researchers are "gaming the system" by running repetitive, useless tasks to create the illusion of high utilization. This behavior stems from intense internal competition for scarce computing resources, leading to inefficient practices designed to protect individual access to hardware.
When building systems with hundreds of thousands of GPUs and millions of components, it's a statistical certainty that something is always broken. Therefore, hardware and software must be architected from the ground up to handle constant, inevitable failures while maintaining performance and service availability.

A major paradox exists in AI development: companies are desperate for scarce GPUs, yet often fail to use them efficiently. Even well-funded labs like XAI report model flops utilization as low as 11%, far below the 40% practical target, due to inconsistent workloads and data transfer bottlenecks.