Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
LLMs excel at coding because internet data (e.g., GitHub) provides complete source code, dependencies, and reasoning. In contrast, mathematical texts online are often just condensed summaries or final proofs, lacking the step-by-step process. This makes it harder for models to learn mathematical reasoning from pre-training alone.

Related Insights
LLMs shine when acting as a 'knowledge extruder'—shaping well-documented, 'in-distribution' concepts into specific code. They fail when the core task is novel problem-solving where deep thinking, not code generation, is the bottleneck. In these cases, the code is the easy part.

Contamination in coding benchmarks is subtle. Instead of just spitting out a known solution, models like GPT-5.2 use implicit knowledge from their training data (e.g., popular codebases) to reason about unstated requirements. This makes it hard to distinguish true capability from memorization, as the model's 'chain of thought' appears logical while relying on leaked information.

The structured, hierarchical nature of code (functions, libraries) provides a powerful training signal for AI models. This helps them infer structural cues applicable to broader reasoning and planning tasks, far beyond just code generation.

A remarkable feature of the current LLM era is that AI researchers can contribute to solving grand challenges in highly specialized domains, such as winning an IMO Gold medal, without possessing deep personal knowledge of that field. The model acts as a universal tool that transcends the operator's expertise.

AI labs deliberately targeted coding first not just to aid developers, but because AI that can write code can help build the next, smarter version of itself. This creates a rapid, self-reinforcing cycle of improvement that accelerates the entire field's progress.

Coding is a unique domain that severely tests LLM capabilities. Unlike other use cases, it involves extremely long-running sessions (up to 30 days for a single task), massive context accumulation from files and command outputs, and requires high precision, making it a key driver for core model research.
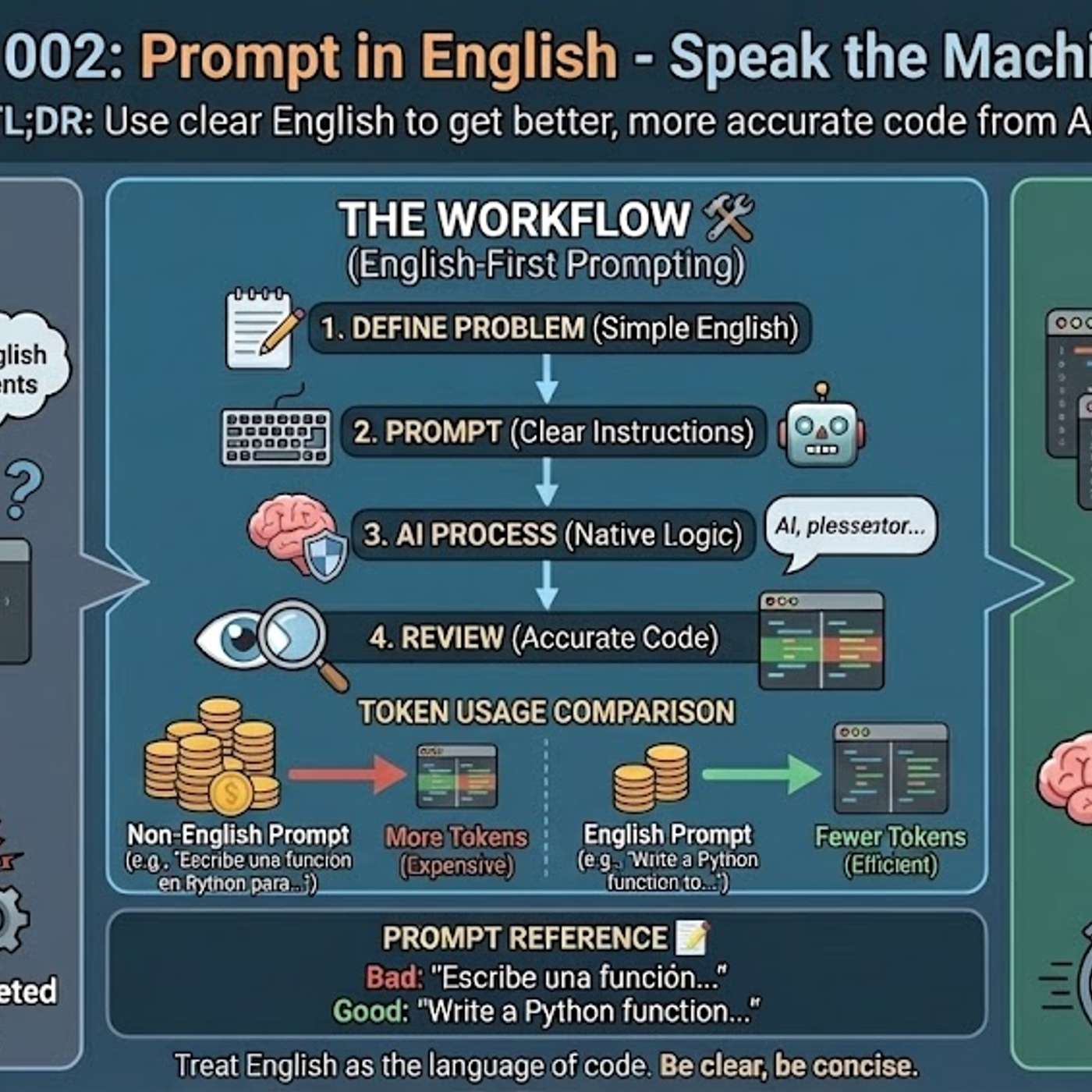
The primary reason AI models generate better code from English prompts is their training data composition. Over 90% of AI training sets, along with most technical libraries and documentation, are in English. This means the models' core reasoning pathways for code-related tasks are fundamentally optimized for English.
To improve LLM reasoning, researchers feed them data that inherently contains structured logic. Training on computer code was an early breakthrough, as it teaches patterns of reasoning far beyond coding itself. Textbooks are another key source for building smaller, effective models.

Replit's CEO argues that today's LLMs are asymptoting on general reasoning tasks. Progress continues only in domains with binary outcomes, like coding, where synthetic data can be generated infinitely. This indicates a fundamental limitation of the current 'ingest the internet' approach for achieving AGI.

Programming is not a linear, left-to-right task; developers constantly check bidirectional dependencies. Transformers' sequential reasoning is a poor match. Diffusion models, which can refine different parts of code simultaneously, offer a more natural and potentially superior architecture for coding tasks.