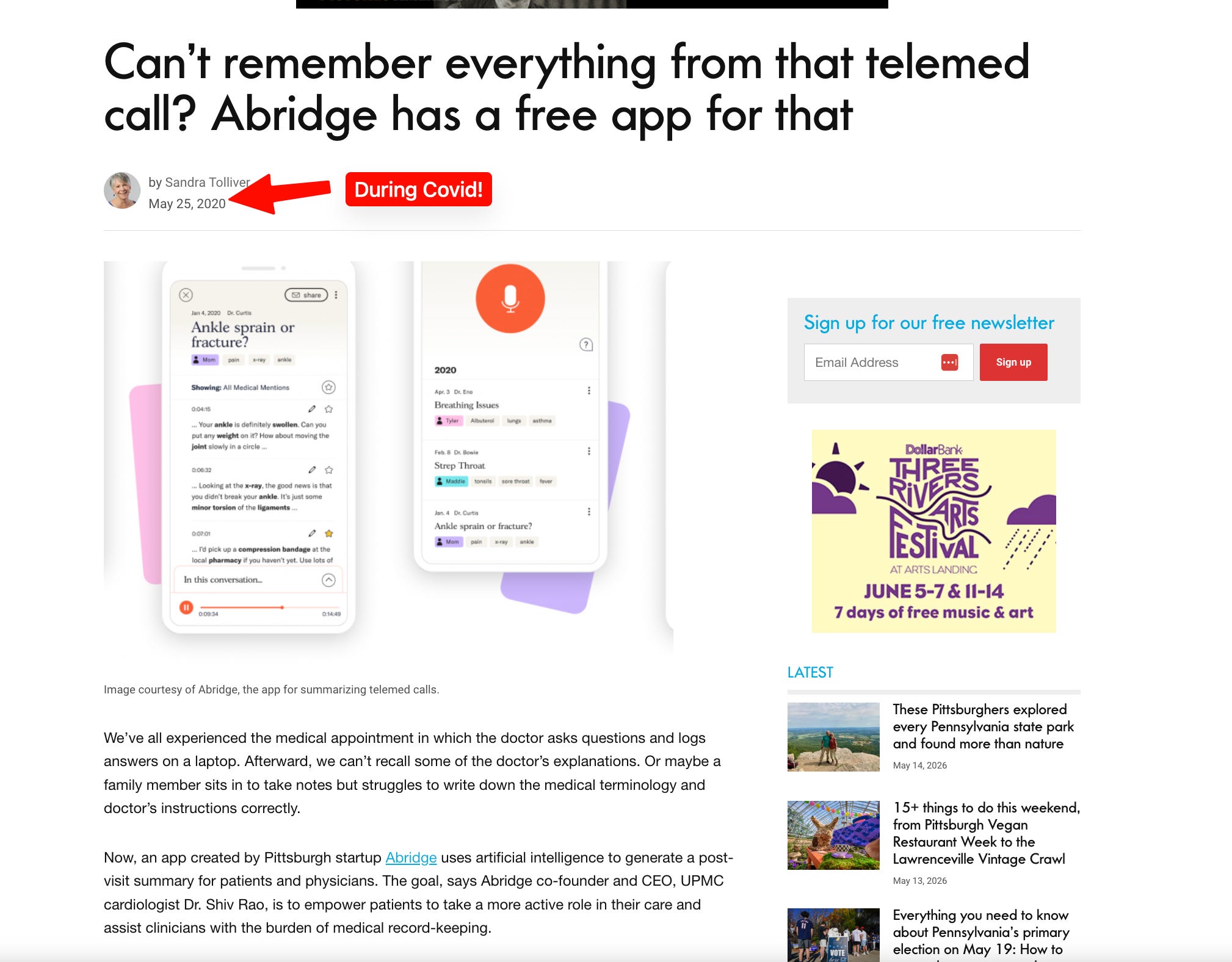
Get your free personalized podcast brief
We scan new podcasts and send you the top 5 insights daily.
Healthcare AI firm Abridge is building its own models with NVIDIA not primarily for cost savings, but to achieve the real-time performance and low latency required for in-workflow clinical tools. This shows that for specialized, high-stakes applications, controlling the model stack for speed is more critical than just reducing token costs.

Related Insights
Emerging cloud providers (“NeoClouds”) are sticking exclusively with NVIDIA, despite alternatives from AMD. The perceived performance risk is too high, as customers demand state-of-the-art inference speed and providers can't risk a multi-billion dollar investment on a non-NVIDIA stack that might offer lower throughput.
Unlike compute-rich giants, AppLovin's bootstrapped culture enforces extreme efficiency in its AI infrastructure. Engineers don't have unlimited GPUs, forcing them to optimize code and models for cost and performance. This constraint-driven approach leads to significant cost savings and a lean operational model.

For complex, long-running AI agent tasks, some users will pay 10x the price for a 10x speed improvement. Cerebras' hardware is ideal for this specific, high-value use case within larger platforms like OpenAI's Codex, compressing tasks from hours to minutes.
To provide high-quality AI insights in real-time without prohibitive costs, Abridge employs a "fast and slow" thinking approach. It uses a constellation of models, where a cheaper, faster model first triages a situation and then hands off complex tasks to a more powerful, expensive model only when necessary.
Nvidia bought Grok not just for its chips, but for its specialized SRAM architecture. This technology excels at low-latency inference, a segment where users are now willing to pay a premium for speed. This strategic purchase diversifies Nvidia's portfolio to capture the emerging, high-value market of agentic reasoning workloads.

The most compelling business reason for enterprises to adopt custom fine-tuning is the need for low latency. For real-time applications like voice bots, large frontier models are too slow. This practical constraint forces companies to use smaller, specialized open-source models.

Nvidia's integration of Grok technology is a strategic move to serve exploding demand for low-latency inference from AI agents. This complements its core GPU business by targeting a specific 25% of the inference market, rather than signaling a wholesale shift away from general-purpose architectures.

The evolution of AI towards complex, autonomous "agents" makes relying solely on the cloud slow and expensive, as users burn through token budgets. Nvidia's bet is that running these agents locally on powerful new PC chips will be faster and cheaper for consumers, driving a major hardware shift away from pure cloud computing.

NVIDIA is creating customized versions of its general-purpose AI models, like Cosmos and Groot, for specific industries. By fine-tuning them on specialized data, such as surgical videos, they can power high-value, niche applications like surgical robots, demonstrating a vertical-focused go-to-market strategy.
At a massive scale, chip design economics flip. For a $1B training run, the potential efficiency savings on compute and inference can far exceed the ~$200M cost to develop a custom ASIC for that specific task. The bottleneck becomes chip production timelines, not money.